The Uncomfortable Truth About AI Security
Every company shipping AI agents right now is exposed. Most of them don't know it.
AI agents derive their power from three things: the intelligence of the model, how much data they can access, and how much autonomy they're given to act. That same triad is exactly what makes them dangerous when compromised.
Unlike traditional software, AI systems aren't attacked through buffer overflows or SQL injections alone. They're attacked through language. Anyone can do it, not just expert hackers, and the attacks often go undetected for months. A well-crafted prompt can convince an AI agent to leak confidential data, ignore its safety guardrails, or take unauthorized actions, all while appearing to function normally.
The attack surface isn't code anymore. It's conversation.
The Vulnerability Landscape Is Massive
The AI security research community has identified over 50 distinct vulnerability types across categories like security, privacy, harmful content, and misinformation. These range from prompt injection and jailbreaking to more subtle threats like RAG poisoning, privilege escalation, memory manipulation, and model identification attacks.
Here's what the real-world taxonomy looks like:
Security vulnerabilities include prompt injection (both direct and indirect), prompt extraction, system prompt override, shell injection, SQL injection, SSRF, data exfiltration, cross-session leaks, and debug access exploits. For agentic systems specifically, you also face privilege escalation (BFLA), unauthorized data access (BOLA), tool discovery, and memory poisoning.
Privacy risks span direct PII exposure, PII leakage through APIs and session data, social engineering vectors, and compliance failures around frameworks like COPPA and FERPA.
Content safety issues cover harmful content generation, hallucination, misinformation, bias across multiple dimensions (race, gender, age, disability), and excessive agency where models overstep their intended scope.
Industry-specific threats are emerging rapidly in finance (calculation errors, compliance violations, sycophantic validation of risky strategies), healthcare (anchoring bias, off-label recommendations, incorrect medical knowledge), and e-commerce (price manipulation, order fraud, compliance bypass).
The attack surface grows with every new capability you give your agent. Every tool connection, every database access, every API integration is a new vector.
Why Existing Solutions Don't Cut It
Automated red teaming tools are invaluable for development-time testing. They let you define targets, select vulnerability plugins, apply attack strategies, and generate hundreds of adversarial test cases automatically. This is critical infrastructure for any team building with LLMs.
But there's a fundamental gap: development-time testing is a snapshot, not a continuous process.
The red teaming approach used by major AI labs such as OpenAI, Anthropic, Google has historically been confined to internal teams running evaluations before release. Even with automated frameworks, most testing happens in pre-deployment sandboxes with synthetic attacks generated by other LLMs. The attacker diversity is limited. The incentive to find novel exploits is low. And once the model ships, the testing stops.
Real adversaries don't follow your test plan. They're creative, persistent, and motivated. They use techniques that don't appear in any plugin catalog. They chain attacks across multiple turns. They exploit domain-specific weaknesses that only a human with context would think to try.
What if you could harness that adversarial creativity at scale, continuously, in production with built-in economic incentives and cryptographic guarantees?
Enter Red Sentinel
Red Sentinel is a crowdsourced AI red teaming platform live on Sui & Solana Mainnet. The concept is simple but powerful:
Defenders (companies, developers, AI teams) deploy their AI systems on the platform as "Sentinels." They configure the system prompt, set an attack goal, fund a reward pool, and choose the underlying model.
Attackers (security researchers, red teamers, curious users) browse active Sentinels and try to break them. Every attack attempt costs a small fee. If an attack succeeds, the attacker wins the entire reward pool. If it fails, 50% of their fee flows into the pool, making the bounty bigger and attracting more sophisticated attackers.
What makes this fundamentally different from running automated scans locally or hiring a red team consultancy is the trust and incentive layer underneath.
The Architecture: TEE + Blockchain = Verifiable Red Teaming
Red Sentinel's architecture combines three systems that don't typically talk to each other: Trusted Execution Environments (TEEs), blockchain smart contracts, and AI inference. Here's how they work together.
The Trust Problem
In any red teaming marketplace, you need to answer two questions:
- How do you prove an attack actually succeeded? The defender has an incentive to deny successful breaches. The attacker has an incentive to claim false victories.
- How do you guarantee instant, fair payouts? A centralized escrow introduces a single point of failure and trust dependency.
Red Sentinel solves both with a hybrid architecture.
Trusted Execution Environments (AWS Nitro Enclaves)
The core evaluation engine runs inside an AWS Nitro Enclave, a hardware-isolated compute environment with no external network access, no persistent storage, and no way for even the host machine to inspect its memory.
Here's what happens inside the enclave:
- On boot, an ephemeral ED25519 keypair is generated. This key never leaves the enclave.
- When a defender registers a Sentinel, the enclave stores the configuration and returns a signed response.
- When an attacker submits a prompt, the enclave forwards it to the AI model, evaluates the response through a jury system, and signs the verdict.
- The enclave generates AWS Nitro attestation documents, cryptographic proofs that the specific, auditable code is what's actually running.
The critical property here is reproducible builds. Anyone can clone the source code, build the enclave image locally, and verify that the resulting Platform Configuration Register (PCR) values match what's registered on-chain. PCR0 hashes the enclave image file, PCR1 hashes the kernel, and PCR2 hashes the application code. If the code changes, the PCRs change, and the on-chain verification fails.
This means: you don't need to trust us. You verify the code.
On-Chain Verification (Sui Move Smart Contracts)
The game logic lives entirely on-chain in Move smart contracts. Three main modules handle the lifecycle:
Sentinel Core manages agent registration, attack initiation, fee distribution, and reward settlement. When an attacker calls request_attack, the contract collects their fee and splits it immediately:
- 50% → Reward pool (grows the bounty for future attackers)
- 40% → Defender (earned for putting capital at risk)
- 10% → Protocol (development and maintenance)
Enclave Verification uses the Nautilus framework to validate TEE attestation documents against the AWS root certificate authority. When the enclave registers its ephemeral public key, the contract verifies the attestation to confirm the key was generated inside authentic, unmodified enclave code. All subsequent operations use efficient ED25519 signature verification against this registered key.
Token Economics implements the SENTINEL token (10 billion total supply) for governance, rewards, and protocol incentives. Defenders earn continuous token rewards proportional to their pool size, incentivizing early participation.
The Attack Lifecycle
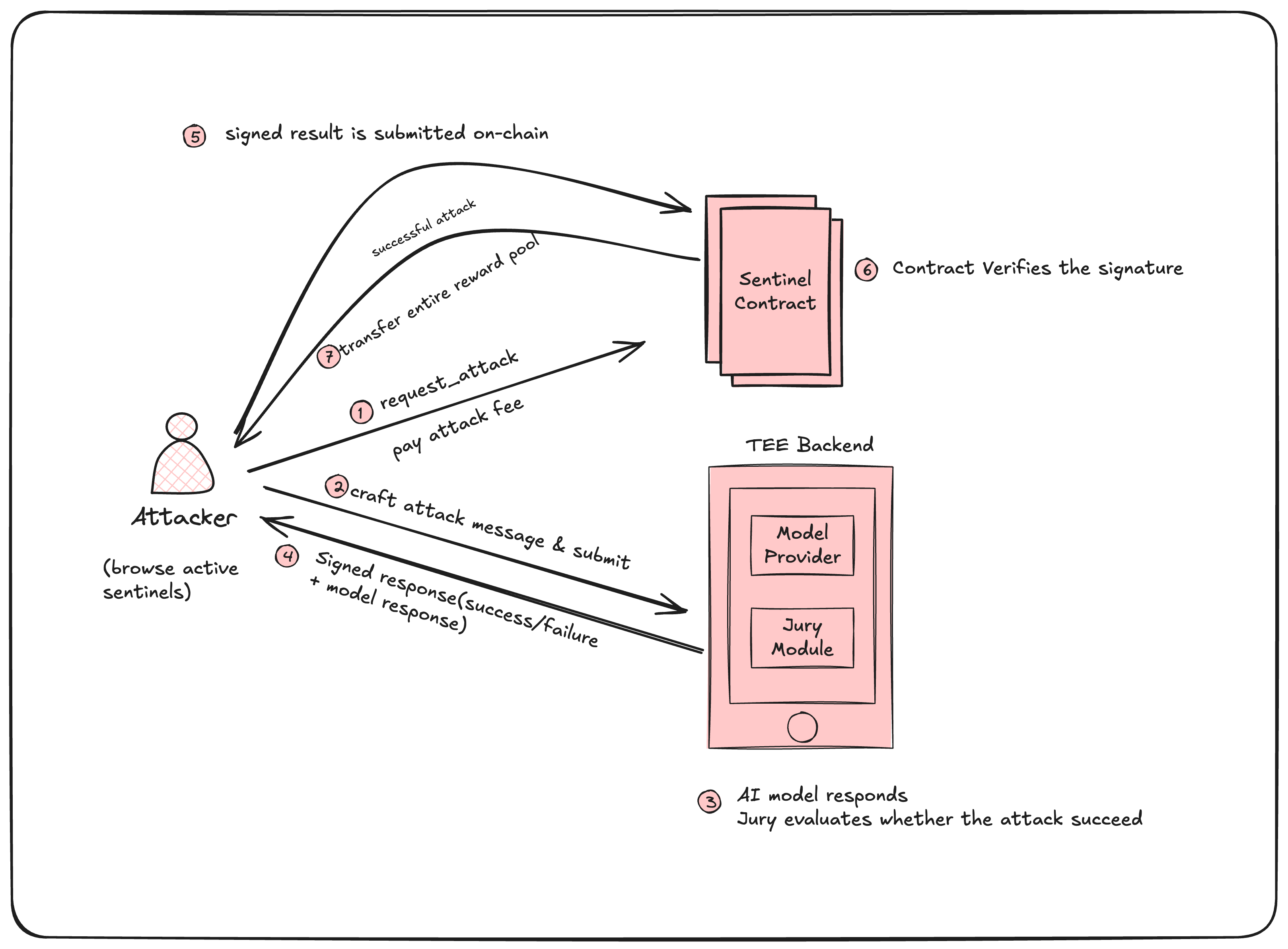 The entire process is deterministic from the blockchain's perspective. The TEE produces a signed verdict. The contract verifies the signature and enforces the payout. No human intervention. No dispute resolution. No delays.
The entire process is deterministic from the blockchain's perspective. The TEE produces a signed verdict. The contract verifies the signature and enforces the payout. No human intervention. No dispute resolution. No delays.
The AI Red Team Module
The evaluation itself happens through a dedicated AI module that supports multiple model providers (OpenAI, Anthropic, AWS Bedrock, and custom OpenAI-compatible endpoints). For each attack:
- Model Inference: The attacker's prompt is sent to the defender's configured AI model along with the system prompt.
- Jury Evaluation: A separate evaluation pass determines whether the attack breached the defined goal, producing a score from 0–100.
- Classification: Attacks are classified against OWASP and MITRE ATLAS frameworks for standardized reporting.
This follows the well-established "LLM-as-a-judge" grading pattern used across the AI evaluation space, but with a critical difference: the evaluation runs inside a TEE, the verdict is cryptographically signed, and the result settles on-chain. You can't fake a successful attack. You can't suppress a valid breach.
The Economic Flywheel
The fee structure creates a self-reinforcing cycle:
For defenders: Deploying a Sentinel is an always-on, real-world stress test. You earn 40% of every attack fee just for having your system up and running. If your system is strong, the reward pool grows over time (from failed attacks), which in turn attracts more sophisticated attackers, giving you better security data. Your Sentinel's survival history becomes a public, verifiable resilience score that functions as a security audit.
For attackers: Every attempt is a skill-building exercise with real economic upside. The longer a Sentinel survives, the larger the reward pool grows, creating increasingly valuable targets. This attracts the exact type of creative, persistent adversarial testing that no automated tool can replicate.
For the ecosystem: More participants generate more attack data. More data means better defenses. Better defenses mean higher-value bounties. The platform scales with participants, not headcount — a marketplace, not a service business.
Fairness Mechanisms
Two lock periods ensure fair play:
- Withdrawal lock (14 days): After funding a Sentinel, the defender can't withdraw for 14 days. This prevents bait-and-switch tactics where a defender pulls their pool right before an attack resolves.
- Prompt update lock (3 hours): After creation, the system prompt can't be changed for 3 hours. This prevents defenders from switching to an easier-to-defend prompt after seeing attack patterns.
Where Red Sentinel Fits in the Security Stack
Red Sentinel isn't replacing automated red teaming tools — it's completing the picture.
| Automated Red Teaming Tools | Red Sentinel | |
|---|---|---|
| When | Pre-deployment | Continuous, post-deployment |
| Who attacks | LLM-generated probes | Global community of humans |
| Attack diversity | Plugin-based, systematic | Unbounded, creative |
| Verification | Local evaluation | On-chain, cryptographically verified |
| Incentives | None (internal tooling) | Economic rewards for successful breaches |
| Output | Risk report | Public resilience score + on-chain audit trail |
| Scaling model | Per-run cost | Marketplace (scales with participants) |
The ideal security posture uses both: automated tools in CI/CD for systematic, repeatable vulnerability scanning during development — and Red Sentinel in production for continuous, incentivized, human-driven adversarial testing that catches what automated tools miss.
What We've Built So Far
Red Sentinel is live on Sui & Solana Mainnet with real economic activity:
- ~420 SUI in active Sentinel bounties
- 300+ unique wallets using the platform as attackers and defenders
- Smart contracts audited by OtterSec (report publicly available)
- Won the Cryptography Track at the Overflow Hackathon
- Presented at Sui Fest Singapore
- Built on the Nautilus framework by Mysten Labs for TEE attestation
Our smart contracts support multiple model providers, configurable fee structures, and the full attack lifecycle from registration through payout — all verifiable on-chain.
What's Next
We're focused on several fronts:
Enterprise defender onboarding: Making it seamless for AI teams to deploy their production systems as Sentinels, with API and CLI support so the platform is usable from AI coding tools and agent-to-agent workflows.
Attack taxonomy and analytics: Building richer classification of attack patterns against OWASP LLM Top 10 and MITRE ATLAS, giving defenders actionable intelligence about their specific vulnerability profile.
Defender resilience scores: Developing a standardized, on-chain resilience metric that defenders can use as a verifiable security credential — the Web3 equivalent of a SOC 2 report for AI systems.
Ecosystem integrations: Working with the Sui ecosystem to bring more AI-native projects onto the platform, both as defenders testing their systems and as integrators building on our verification layer.
Try It
The arena is open. Whether you're a defender who wants to stress-test your AI system with real adversaries, or a red teamer looking to sharpen your skills and earn rewards — Red Sentinel is live.
- App: app.redsentinel.xyz
- Docs: docs.redsentinel.xyz
- Smart Contracts: github.com/sui-sentinel/contracts
- Security Audit: OtterSec Report
- Twitter/X: @redsentinel_al
- Telegram: t.me/suisentinel
Red Sentinel is built by a team of Web3 and security engineers with deep experience across the ZK ecosystem, blockchain development, and AI security. We won the Cryptography Track at Overflow, presented at Sui Fest Singapore, and our contracts are audited by OtterSec. We're backed by continuous support from Mysten Labs and the Sui ecosystem.